01redis
# 1.Redis的优势-能干什么
- 1.性能极高 – Redis能读的速度是110000次/秒,写的速度是81000次/秒
- 2.数据类型丰富,不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构
- 3.Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用
- 4.Redis支持数据的备份,即master-slave模式的数据备份
# 2.Redis的安装
# 2.1 官网地址
https://redis.io/ (opens new window)
中文:
- http://www.redis.cn/ (opens new window)
- https://www.redis.com.cn/documentation.html (opens new window)
# 2.2 下载安装
Linux安装,以centos为例
yum install wget pwd /home/app/redis wget https://download.redis.io/releases/redis-7.0.0.tar.gz ## 解压 tar -zxvf redis-7.0.0.tar.gz ## 错误 MAKE hiredis cd hiredis && make static make[3]: 进入目录“/home/app/redis/redis-7.0.0/deps/hiredis” cc -std=c99 -c -O3 -fPIC -Wall -W -Wstrict-prototypes -Wwrite-strings -Wno-missing-field-initializers -g -ggdb -pedantic alloc.c make[3]: cc:命令未找到 make[3]: *** [alloc.o] 错误 127 make[3]: 离开目录“/home/app/redis/redis-7.0.0/deps/hiredis” make[2]: *** [hiredis] 错误 2 make[2]: 离开目录“/home/app/redis/redis-7.0.0/deps” make[1]: [persist-settings] 错误 2 (忽略) CC adlist.o /bin/sh: cc: 未找到命令 make[1]: *** [adlist.o] 错误 127 make[1]: 离开目录“/home/app/redis/redis-7.0.0/src” make: *** [all] 错误 2 ## 安装gcc sudo yum install gcc ## 缺少python3 which: no python3 in (/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/home/app/jdk1.8.0_401/bin:/home/app/apache-maven-3.8.1/bin:/root/bin) ## 安装python3 sudo yum install python3 ## 执行make 编译 make make install # cd src # ./redis-server 修改配置 bind 0.0.0.0 protected-mode no requirepass 123456 # cd src redis-server /home/app/redis/redis-7.0.0/redis.conf /usr/local/bin/redis-server /home/app/redis/redis-7.0.0/redis.conf # cd src # ./redis-cli redis> set foo bar OK redis> get foo "bar"1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62docker 安装
version: '3'
services:
redis:
image: registry.cn-hangzhou.aliyuncs.com/zhengqing/redis:7.0.5 # 镜像'redis:7.0.5'
container_name: redis # 容器名为'redis'
# restart: unless-stopped # 指定容器退出后的重启策略为始终重启,但是不考虑在Docker守护进程启动时就已经停止了的容器
command: redis-server --requirepass 123456 --appendonly yes # 启动redis服务并添加密码为:123456,并开启redis持久化配置
environment: # 设置环境变量,相当于docker run命令中的-e
TZ: Asia/Shanghai
LANG: en_US.UTF-8
volumes: # 数据卷挂载路径设置,将本机目录映射到容器目录
- "./redis/data:/data"
- "./redis/config/redis.conf:/etc/redis/redis.conf" # `redis.conf`文件内容`http://download.redis.io/redis-stable/redis.conf`
ports: # 映射端口
- "6379:6379"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
进入redis命令行
chmod -R 777 ./redis
# 运行 -- 单机模式
docker-compose -f docker-compose-redis.yml -p redis up -d
docker exec -it redis redis-cli -a 123456
2
3
4
5
# 3.文档资料
源码地址 https://github.com/redis/redis (opens new window)
在线测试: https://try.redis.io/ (opens new window)
参考命令: http://doc.redisfans.com/ (opens new window)
# 4.Redis的10大数据类型
这里说的数据类型是value的数据类型,key的类型都是字符串
# 4.1 redis字符串(String)
String(字符串),string是redis最基本的类型,一个key对应一个value,string类型是二进制安全的,意思是redis的string可以包含任何数据,比如jpg图片或者序列化的对象 。
string类型是Redis最基本的数据类型,一个redis中字符串value最多可以是512M
# 4.2 redis列表(List)
List(列表),Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)
它的底层实际是个双端链表,最多可以包含 2^32 - 1 个元素 (4294967295, 每个列表超过40亿个元素)
# 4.3 redis哈希表(Hash)
Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象。
Redis 中每个 hash 可以存储 2^32 - 1 键值对(40多亿)
# 4.4 redis集合(Set)
Set(集合)
Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据,集合对象的编码可以是 intset 或者 hashtable。
Redis 中Set集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
集合中最大的成员数为 2^32 - 1 (4294967295, 每个集合可存储40多亿个成员)
# 4.5 redis有序集合(ZSet)
zset(sorted set:有序集合)
Redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数,redis正是通过分数来为集合中的成员进行从小到大的排序。
zset的成员是唯一的,但分数(score)却可以重复。
zset集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。 集合中最大的成员数为 2^32 - 1
# 4.6redis地理空间(GEO)
Redis GEO 主要用于存储地理位置信息,并对存储的信息进行操作,包括
添加地理位置的坐标。
获取地理位置的坐标。
计算两个位置之间的距离。
根据用户给定的经纬度坐标来获取指定范围内的地理位置集合
# 4.7redis基数统计(HyperLogLog)
HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
# 4.8 redis位图(bitmap)
由0和1状态表现的二进制位的bit数组
# 4.9 redis位域(bitfield)
通过bitfield命令可以一次性操作多个比特位域(指的是连续的多个比特位),它会执行一系列操作并返回一个响应数组,这个数组中的元素对应参数列表中的相应操作的执行结果。
说白了就是通过bitfield命令我们可以一次性对多个比特位域进行操作。
# 4.10 redis流(Stream)
Redis Stream 是 Redis 5.0 版本新增加的数据结构。
Redis Stream 主要用于消息队列(MQ,Message Queue),Redis 本身是有一个 Redis 发布订阅 (pub/sub) 来实现消息队列的功能,但它有个缺点就是消息无法持久化,如果出现网络断开、Redis 宕机等,消息就会被丢弃。
简单来说发布订阅 (pub/sub) 可以分发消息,但无法记录历史消息。
而 Redis Stream 提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失
# 5. 文档
官网:https://redis.io/commands/ (opens new window)
中文:http://www.redis.cn/commands.html (opens new window)
# 6.Redis key
key的操作:Redis Key (opens new window)
常用操作
keys *获取所有的keyexists key判断某一个key。是否存在type key查看key的数据类型del key删除keyunlink key非阻塞删除,仅仅将keys从keyspace元数据中删除,真正的删除会在后续异步中操作。ttl key查看还有多少秒过期,-1表示永不过期,-2表示已过期expire key为给定的key设置过期时间move key db将当前数据库的 key移动到给定的数据库 db 当中select dbindex切换数据库【0-15】,默认为0dbsize查看当前数据库key的数量flushdb清空当前库flushall清空所有数据库
# 7.String 类型
最常用的类型,Redis 字符串(String) | 菜鸟教程 (runoob.com) (opens new window)
单值单value
最常用的:
set key value,get keyset命令详情: Redis SET 命令 设置键的字符串值 (opens new window)
EXseconds – 设置键key的过期时间,单位时秒PXmilliseconds – 设置键key的过期时间,单位时毫秒NX– 只有键key不存在的时候才会设置key的值XX– 只有键key存在的时候才会设置key的值KEEPTTL-- 获取 key 的过期时间- GET (opens new window) -- 返回 key 存储的值,如果 key 不存在返回空
## nx key不存在,设置 nsp2:db0> set k1 v1 nx OK nsp2:db0> set k1 v2 nx nsp2:db0> get k1 v1 nsp2:db0> ## 设置过期时间 nsp2:db0> set k2 ve ex 100 OK nsp2:db0> ttl k2 941
2
3
4
5
6
7
8
9
10
11
12
13
14同时设置、获取多个值,mset、mget
nsp2:db0> mset k1 v2 k2 v2 k3 v3 OK nsp2:db0> mget k1 k2 k3 1) "v2" 2) "v2" 3) "v3"1
2
3
4
5
6数值的增减,
incr key,decr key获取字符串长度和内容追加。
strlen keyappend key value分布式锁;setnx key value 、setex
# 8.列表List
类型:单key多个value
一个双端链表的结构,容量是2的32次方减1个元素,大概40多亿,主要功能有push/pop等,一般用在栈、队列、消息队列等场景。
- left、right都可以插入添加;
- 如果键不存在,创建新的链表;
- 如果键已存在,新增内容;
- 如果值全移除,对应的键也就消失了。
- 它的底层实际是个双向链表,对两端的操作性能很高,通过索引下标的操作中间的节点性能会较差。
LPUSH 、RPUSH、LRANGE
nsp2:db0> lpush list1 1 2 3 4 5 6 6 nsp2:db0> lrange list1 0 -1 1) "6" 2) "5" 3) "4" 4) "3" 5) "2" 6) "1" nsp2:db0> rpush list2 11 22 33 44 55 66 6 nsp2:db0> lrange list2 0 -1 1) "11" 2) "22" 3) "33" 4) "44" 5) "55" 6) "66"1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19lopo、rpop,弹出元素
lindex 按照索引下标获得元素(从上到下)
nsp2:db0> lrange list1 0 -1 1) "6" 2) "5" 3) "4" 4) "3" 5) "2" 6) "1" nsp2:db0> lindex list1 0 6 nsp2:db0> lindex list1 5 11
2
3
4
5
6
7
8
9
10
11llen 列表中的元素个数
lrem key 数字n 给定值v。删除n个等于v的元素
ltrim key 开始index 结束index,截取指定范围后,再赋值给key
RPOPLPUSH SOURCE_KEY_NAME DESTINATION_KEY_NAME, 移除列表的最后一个元素,并将该元素添加到另一个列表并返回
LSET KEY_NAME INDEX VALUE,Redis Lset 通过索引来设置元素的值。
LINSERT key BEFORE|AFTER pivot value,Redis Linsert 命令用于在列表的元素前或者后插入元素。当指定元素不存在于列表中时,不执行任何操作。
# 9.hash哈希
Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象。类似于
Map<String,Map<Object,Object>>hset、hget、hmset、hmget、hgetall、hdel
hlen:获取某个key内的全部数量
hexists key filed:查看哈希表 key 中,指定的字段是否存在
hincrby、hincrbyfloat,增加整数、小数
hsetnx:不存在,则添加
案例
nsp2:db0> hset user:001 id 11 name zs age 18 3 nsp2:db0> hget user:001 id 11 nsp2:db0> hget user:001 name zs nsp2:db0> hgetall user:001 1) "id" 2) "11" 3) "name" 4) "zs" 5) "age" 6) "18" nsp2:db0> hdel user:001 age 1 nsp2:db0> hgetall user:001 1) "id" 2) "11" 3) "name" 4) "zs" nsp2:db0> hlen user:001 2 nsp2:db0> hexists user:001 name 1 nsp2:db0> hexists user:001 age 0 nsp2:db0> hkesy user:001 ERR unknown command 'hkesy', with args beginning with: 'user:001' nsp2:db0> hkeys user:001 1) "id" 2) "name" nsp2:db0> hvals user:001 1) "11" 2) "zs" nsp2:db0> hset user:001 age 12 1 nsp2:db0> hset user:001 source 12.1 1 nsp2:db0> hgetall user:001 1) "id" 2) "11" 3) "name" 4) "zs" 5) "age" 6) "12" 7) "source" 8) "12.1" nsp2:db0> hincrby user:001 age 1 13 nsp2:db0> hincrby user:001 age 1 14 nsp2:db0> hincrby user:001 age 2 16 nsp2:db0> hincrbyfloat user:001 source 0.2 12.3 nsp2:db0> hset user:001 email 11@qq.com 1 nsp2:db0> hset user:001 email 11@qq.com 01
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61应用场景:早期的jd购物车,中小型企业的购物车
# 10.set集合
常用命令:Redis 集合(Set) | 菜鸟教程 (runoob.com) (opens new window)
Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。集合对象的编码可以是 intset 或者 hashtable。Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
SADD KEY_NAME VALUE1..VALUEN命令将一个或多个成员元素加入到集合中,已经存在于集合的成员元素将被忽略。假如集合 key 不存在,则创建一个只包含添加的元素作成员的集合。当集合 key 不是集合类型时,返回一个错误。
SMEMBERS key:返回集合中的所有元素SISMEMBER KEY VALUE: 判断集合中的元素是否存在SREM KEY MEMBER1..MEMBERN:移除集合中的元素。SCARD KEY_NAME:获取元素中的个数。SRANDMEMBER KEY [count]:随机展示设置数字的元素。元素不删除SPOP key [count]: 随机弹出指定元素个数,元素删除。SMOVE SOURCE DESTINATION MEMBER: 命令将指定成员 member 元素从 source 集合移动到 destination 集合。SMOVE 是原子性操作。
集合运算
SDIFF FIRST_KEY OTHER_KEY1..OTHER_KEYN: Redis Sdiff 命令返回第一个集合与其他集合之间的差异,也可以认为说第一个集合中独有的元素。不存在的集合 key 将视为空集。差集的结果来自前面的 FIRST_KEY ,而不是后面的 OTHER_KEY1,也不是整个 FIRST_KEY OTHER_KEY1..OTHER_KEYN 的差集
key1 = {a,b,c,d} key2 = {c} key3 = {a,c,e} SDIFF key1 key2 key3 = {b,d}1
2
3
4SUNION KEY KEY1..KEYN:Redis Sunion 命令返回给定集合的并集。不存在的集合 key 被视为空集。SINTER KEY KEY1..KEYN:Redis Sinter 命令返回给定所有给定集合的交集。 不存在的集合 key 被视为空集。 当给定集合当中有一个空集时,结果也为空集(根据集合运算定律)。应用场景
- 小程序抽奖。从set集合中,随机取一个元素
- 朋友圈点赞,查看同赞的盆友。集合的交集
# 11.zset有序集合
Redis 有序集合和集合一样也是 string 类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个 double 类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序。
有序集合的成员是唯一的,但分数(score)却可以重复。
常用 Redis 有序集合(sorted set) | 菜鸟教程 (runoob.com) (opens new window)
ZADD KEY_NAME SCORE1 VALUE1.. SCOREN VALUENnsp2:db0> ZADD myzset 1 "one" 1 nsp2:db0> ZADD myzset 1 "uno" 1 nsp2:db0> ZADD myzset 2 "two" 3 "three" 2 nsp2:db0> ZRANGE myzset 0 -1 WITHSCORES 1) 1) "one" 2) 1 2) 1) "uno" 2) 1 3) 1) "two" 2) 2 4) 1) "three" 2) 31
2
3
4
5
6
7
8
9
10
11
12
13
14
15ZRANGE key start stop [WITHSCORES]: Redis Zrange 返回有序集中,指定区间内的成员。其中成员的位置按分数值递增(从小到大)来排序。下标参数 start 和 stop 都以 0 为底,也就是说,以 0 表示有序集第一个成员,以 1 表示有序集第二个成员,以此类推。你也可以使用负数下标,以 -1 表示最后一个成员, -2 表示倒数第二个成员,以此类推。
ZREVRANGE key start stop [WITHSCORES]:Redis Zrevrange 命令返回有序集中,指定区间内的成员。其中成员的位置按分数值递减(从大到小)来排列。nsp2:db0> zrevrange myzset 0 -1 1) "three" 2) "two" 3) "uno" 4) "one" nsp2:db0> zrevrange myzset 0 -1 withscores 1) 1) "three" 2) 3 2) 1) "two" 2) 2 3) 1) "uno" 2) 1 4) 1) "one" 2) 1 nsp2:db0>1
2
3
4
5
6
7
8
9
10
11
12
13
14
15ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count]: Redis Zrevrangebyscore 返回有序集中指定分数区间内的所有的成员。有序集成员按分数值递减(从大到小)的次序排列。
nsp2:db0> ZREVRANGEBYSCORE myzset 3 2
1) "three"
2) "two"
nsp2:db0> ZREVRANGEBYSCORE myzset 3 2 withscores
1) 1) "three"
2) 3
2) 1) "two"
2) 2
2
3
4
5
6
7
8
ZSCORE key member: Redis Zscore 命令返回有序集中,成员的分数值。 如果成员元素不是有序集 key 的成员,或 key 不存在,返回 nil 。nsp2:db0> zscore myzset uno 11
2ZCARD KEY_NAME: Redis Zcard 命令用于计算集合中元素的数量。ZCOUNT key min max:Redis Zcount 命令用于计算有序集合中指定分数区间的成员数量。ZREM key member [member ...]: Redis Zrem 命令用于移除有序集中的一个或多个成员,不存在的成员将被忽略。当 key 存在但不是有序集类型时,返回一个错误。ZINCRBY key increment member: Redis Zincrby 命令对有序集合中指定成员的分数加上增量 increment,可以通过传递一个负数值 increment ,让分数减去相应的值,比如 ZINCRBY key -5 member ,就是让 member 的 score 值减去 5 。当 key 不存在,或分数不是 key 的成员时, ZINCRBY key increment member 等同于 ZADD key increment member 。
# 12.位图Bitmaps
由0和1状态表现的二进制位的bit数组
能做什么
- 用户是否登陆过Y、N,比如京东每日签到送京豆
- 电影、广告是否被点击播放过
- 钉钉打卡上下班,签到统计
说明
说明:用String类型作为底层数据结构实现的一种统计二值状态的数据类型。
位图本质是数组,它是基于String数据类型的按位的操作。该数组由多个二进制位组成,每个二进制位都对应一个偏移量(我们称之为一个索引)。
基本命令
setbit key offset value: setbit 键 偏移位 只能零或者1.Bitmap的偏移量是从零开始算的
nsp2:db0> setbit k1 1 1 0 nsp2:db0> setbit k1 7 1 0 nsp2:db0> get k1 A1
2
3
4
5
6gbit key offset
nsp2:db0> getbit k1 0 0 nsp2:db0> getbit k1 1 11
2
3
4strlen 不是字符串长度而是占据几个字节,超过8位后自己按照8位一组一byte再扩容
nsp2:db0> strlen k1 11
2bitop: 连续2天都签到的用户
加入某个网站或者系统,它的用户有1000W,做个用户id和位置的映射
bitcount :全部键里面含有1的有多少个?
nsp2:db0> bitcount k1 21
2
引用场景
- 一年365天,全年天天登陆占用多少字节
- 按照年:按年去存储一个用户的签到情况,365 天只需要 365 / 8 ≈ 46 Byte,1000W 用户量一年也只需要 44 MB 就足够了。
- 此外,在实际使用时,最好对Bitmap设置过期时间,让Redis自动删除不再需要的签到记录以节省内存开销。
# 13.基数统计HyperLogLog
Redis HyperLogLog | 菜鸟教程 (runoob.com) (opens new window)
- 用于基数估计算法的数据结构。
- 常用于统计唯一值的近似值。
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
需求
- 统计某个网站的UV、统计某个文章的UV
- Unique Visitor,独立访客,一般理解为客户端IP
- 需要去重考虑
- 用户搜索网站关键词的数量
- 统计用户每天搜索不同词条个数
是什么
- 去重复统计功能的基数估计算法-就是HyperLogLog
- 基数
- 是一种数据集,去重复后的真实个数
- 比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。
- 基数统计:用于统计一个集合中不重复的元素个数,就是对集合去重复后剩余元素的计算
- 去重脱水后的真实数据
基本命令
# 14.Redis地理空间(GEO)
Redis GEO | 菜鸟教程 (runoob.com) (opens new window)
命令
geoadd:geoadd 用于存储指定的地理空间位置,可以将一个或多个经度(longitude)、纬度(latitude)、位置名称(member)添加到指定的 key 中。
GEOADD key longitude latitude member [longitude latitude member ...] nsp2:db0> GEOADD Sicily 13.361389 38.115556 "Palermo" 15.087269 37.502669 "Catania" 2 nsp2:db0> GEODIST Sicily Palermo Catania 166274.1516 nsp2:db0> GEORADIUS Sicily 15 37 100 km 1) "Catania" nsp2:db0> GEORADIUS Sicily 15 37 200 km 1) "Palermo" 2) "Catania"1
2
3
4
5
6
7
8
9
10
11geopos :用于从给定的 key 里返回所有指定名称(member)的位置(经度和纬度),不存在的返回 nil。
GEOPOS key member [member ...] nsp2:db0> GEOPOS Sicily Palermo Catania NonExisting 1) 1) 13.361389338970184 2) 38.1155563954963 2) 1) 15.087267458438873 2) 37.50266842333162 3)1
2
3
4
5
6
7
8geodist 用于返回两个给定位置之间的距离。
- member1 member2 为两个地理位置。
- 最后一个距离单位参数说明:
- m :米,默认单位。
- km :千米。
- mi :英里。
- ft :英尺。
GEODIST key member1 member2 [m|km|ft|mi] nsp2:db0> GEODIST Sicily Palermo Catania 166274.1516 nsp2:db0> GEODIST Sicily Palermo Catania km 166.27421
2
3
4
5
6georadius、georadiusbymember
georadius 以给定的经纬度为中心, 返回键包含的位置元素当中, 与中心的距离不超过给定最大距离的所有位置元素。
georadiusbymember 和 GEORADIUS 命令一样, 都可以找出位于指定范围内的元素, 但是 georadiusbymember 的中心点是由给定的位置元素决定的, 而不是使用经度和纬度来决定中心点。
georadius 与 georadiusbymember 语法格式如下:
GEORADIUS key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key] GEORADIUSBYMEMBER key member radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]1
2参数说明:
- WITHDIST: 在返回位置元素的同时, 将位置元素与中心之间的距离也一并返回。
- WITHCOORD: 将位置元素的经度和纬度也一并返回。
- WITHHASH: 以 52 位有符号整数的形式, 返回位置元素经过原始 geohash 编码的有序集合分值。 这个选项主要用于底层应用或者调试, 实际中的作用并不大。
- COUNT 限定返回的记录数。
- ASC: 查找结果根据距离从近到远排序。
- DESC: 查找结果根据从远到近排序。
nsp2:db0> GEORADIUS Sicily 15 37 200 km WITHDIST 1) 1) "Palermo" 2) "190.4424" 2) 1) "Catania" 2) "56.4413" nsp2:db0> GEORADIUS Sicily 15 37 200 km WITHCOORD 1) 1) "Palermo" 2) 1) 13.361389338970184 2) 38.1155563954963 2) 1) "Catania" 2) 1) 15.087267458438873 2) 37.502668423331621
2
3
4
5
6
7
8
9
10
11
12geohash
Redis GEO 使用 geohash 来保存地理位置的坐标。
geohash 用于获取一个或多个位置元素的 geohash 值。
GEOHASH key member [member ...] nsp2:db0> GEOHASH Sicily Palermo Catania 1) "sqc8b49rny0" 2) "sqdtr74hyu0" nsp2:db0>1
2
3
4
5
# 15.Redis Stream
是什么
- Redis Stream 是 Redis 5.0 版本新增加的数据结构。
- Redis Stream 主要用于消息队列(MQ,Message Queue),Redis 本身是有一个 Redis 发布订阅 (pub/sub) 来实现消息队列的功能,但它有个缺点就是消息无法持久化,如果出现网络断开、Redis 宕机等,消息就会被丢弃。
- 简单来说发布订阅 (pub/sub) 可以分发消息,但无法记录历史消息。
- 而 Redis Stream 提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失。
- Redis Stream 的结构如下所示,它有一个消息链表,将所有加入的消息都串起来,每个消息都有一个唯一的 ID 和对应的内容:
Redis Stream | 菜鸟教程 (runoob.com) (opens new window)
能干什么
- 实现消息队列,它支持消息的持久化、支持自动生成全局唯一 ID、支持ack确认消息的模式、支持消费组模式等,让消息队列更加的稳定和可靠
基本命令
消息队列相关命令:
- XADD - 添加消息到末尾
- XTRIM - 对流进行修剪,限制长度
- XDEL - 删除消息
- XLEN - 获取流包含的元素数量,即消息长度
- XRANGE - 获取消息列表,会自动过滤已经删除的消息
- XREVRANGE - 反向获取消息列表,ID 从大到小
- XREAD - 以阻塞或非阻塞方式获取消息列表
消费者组相关命令:
- XGROUP CREATE - 创建消费者组
- XREADGROUP GROUP - 读取消费者组中的消息
- XACK - 将消息标记为"已处理"
- XGROUP SETID - 为消费者组设置新的最后递送消息ID
- XGROUP DELCONSUMER - 删除消费者
- XGROUP DESTROY - 删除消费者组
- XPENDING - 显示待处理消息的相关信息
- XCLAIM - 转移消息的归属权
- XINFO - 查看流和消费者组的相关信息;
- XINFO GROUPS - 打印消费者组的信息;
- XINFO STREAM - 打印流信息
# 15.Redis的Stream流
文档Redis Stream | 菜鸟教程 (runoob.com) (opens new window)
Redis Stream 主要用于消息队列(MQ,Message Queue),Redis 本身是有一个 Redis 发布订阅 (pub/sub) 来实现消息队列的功能,但它有个缺点就是消息无法持久化,如果出现网络断开、Redis 宕机等,消息就会被丢弃。
简单来说发布订阅 (pub/sub) 可以分发消息,但无法记录历史消息。
而 Redis Stream 提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失。
Redis Stream 的结构如下所示,它有一个消息链表,将所有加入的消息都串起来,每个消息都有一个唯一的 ID 和对应的内容:
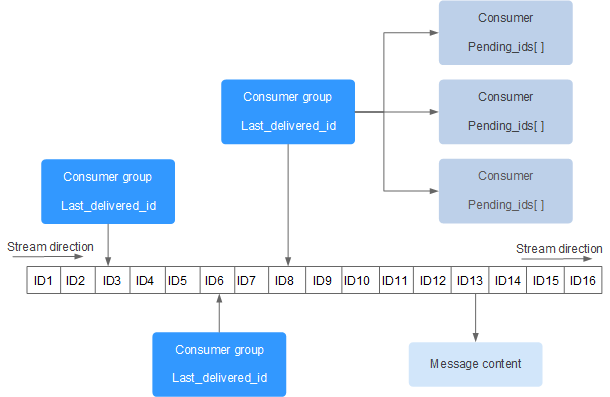
操作命令
- xadd
nsp2:db0> xadd mystream * id 11 cname zs
1722262632117-0
nsp2:db0> xadd mystream * id 12 cname ls
1722262645366-0
nsp2:db0> xadd mystream * k1 v1 k2 v2 k3 v3
1722262695684-0
2
3
4
5
6
- xrange
nsp2:db0> xrange mystream - +
1) 1) "1722262632117-0"
2) 1) "id"
2) "11"
3) "cname"
4) "zs"
2) 1) "1722262645366-0"
2) 1) "id"
2) "12"
3) "cname"
4) "ls"
3) 1) "1722262695684-0"
2) 1) "k1"
2) "v1"
3) "k2"
4) "v2"
5) "k3"
6) "v3"
只返回两条
nsp2:db0> xrange mystream - + count 2
1) 1) "1722262632117-0"
2) 1) "id"
2) "11"
3) "cname"
4) "zs"
2) 1) "1722262645366-0"
2) 1) "id"
2) "12"
3) "cname"
4) "ls"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
- xrevrange
nsp2:db0> xrevrange mystream + -
1) 1) "1722262695684-0"
2) 1) "k1"
2) "v1"
3) "k2"
4) "v2"
5) "k3"
6) "v3"
2) 1) "1722262645366-0"
2) 1) "id"
2) "12"
3) "cname"
4) "ls"
3) 1) "1722262632117-0"
2) 1) "id"
2) "11"
3) "cname"
4) "zs"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
- xdel
nsp2:db0> xdel mystream 1722262632117-0
1
nsp2:db0> xrevrange mystream + -
1) 1) "1722262695684-0"
2) 1) "k1"
2) "v1"
3) "k2"
4) "v2"
5) "k3"
6) "v3"
2) 1) "1722262645366-0"
2) 1) "id"
2) "12"
3) "cname"
4) "ls"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- xlen
nsp2:db0> xlen mystream
2
2
XTRIM 使用 XTRIM 对流进行修剪,限制长度, 语法格式:
XTRIM key MAXLEN [~] count1- key :队列名称
- MAXLEN :长度
- count :数量
127.0.0.1:6379> XADD mystream * field1 A field2 B field3 C field4 D
"1601372434568-0"
127.0.0.1:6379> XTRIM mystream MAXLEN 2
(integer) 0
127.0.0.1:6379> XRANGE mystream - +
1) 1) "1601372434568-0"
2) 1) "field1"
2) "A"
3) "field2"
4) "B"
5) "field3"
6) "C"
7) "field4"
8) "D"
127.0.0.1:6379>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- xread
nsp2:db0> xrange mystream - +
1) 1) "1722263530333-0"
2) 1) "k3"
2) "v3"
3) "k4"
4) "v4"
2) 1) "1722263539031-0"
2) 1) "k5"
2) "v5"
3) 1) "1722263606454-0"
2) 1) "k6"
2) "v6"
4) 1) "1722263625919-0"
2) 1) "k7"
2) "v7"
5) 1) "1722263631705-0"
2) 1) "k8"
2) "v8"
nsp2:db0> xread count 2 streams mystream $
nil
nsp2:db0> xread count 2 streams mystream 0-0
1) "mystream"
2) 1) 1) "1722263530333-0"
2) 1) "k3"
2) "v3"
3) "k4"
4) "v4"
2) 1) "1722263539031-0"
2) 1) "k5"
2) "v5"
阻塞读取
> xread count 1 block 0 streams mystream $
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
消费者
nsp2:db0> xgroup create mystream groupX $
OK
nsp2:db0> xgroup create mystream groupA 0
OK
nsp2:db0> xgroup create mystream groupB 0
OK
nsp2:db0> xreadgroup group groupA consumer1 streams mystream >
1) "mystream"
2) 1) 1) "1722263530333-0"
2) 1) "k3"
2) "v3"
3) "k4"
4) "v4"
2) 1) "1722263539031-0"
2) 1) "k5"
2) "v5"
3) 1) "1722263606454-0"
2) 1) "k6"
2) "v6"
4) 1) "1722263625919-0"
2) 1) "k7"
2) "v7"
5) 1) "1722263631705-0"
2) 1) "k8"
2) "v8"
# 组内已经有消费之读取消息后,第二个消费读取不到数据,默认情况下,
# 不同组的消费者可以读取到消息
nsp2:db0> xreadgroup group groupA consumer2 streams mystream >
nsp2:db0>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]
- group :消费组名
- consumer :消费者名。
- count : 读取数量。
- milliseconds : 阻塞毫秒数。
- key : 队列名。
- ID : 消息 ID。
xpending
nsp2:db0> xpending mystream groupA
1) 5
2) "1722263530333-0"
3) "1722263631705-0"
4) 1) 1) "consumer1"
2) "5"
nsp2:db0>
2
3
4
5
6
7
xack
nsp2:db0> xpending mystream groupA - + 10 consumer1
1) 1) "1722263530333-0"
2) "consumer1"
3) 694508
4) 1
2) 1) "1722263539031-0"
2) "consumer1"
3) 694508
4) 1
3) 1) "1722263606454-0"
2) "consumer1"
3) 694508
4) 1
4) 1) "1722263625919-0"
2) "consumer1"
3) 694508
4) 1
5) 1) "1722263631705-0"
2) "consumer1"
3) 694508
4) 1
nsp2:db0> xack mystream groupA 1722263530333-0
1
nsp2:db0> xpending mystream groupA - + 10 consumer1
1) 1) "1722263539031-0"
2) "consumer1"
3) 768607
4) 1
2) 1) "1722263606454-0"
2) "consumer1"
3) 768607
4) 1
3) 1) "1722263625919-0"
2) "consumer1"
3) 768607
4) 1
4) 1) "1722263631705-0"
2) "consumer1"
3) 768607
4) 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40