redis缓存双写一致性
# 1.面试题
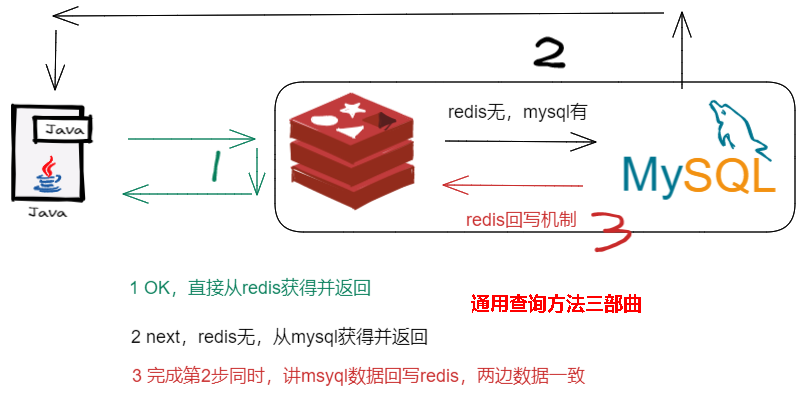
- 你只要用缓存,就可能会涉及到redis缓存与数据库双存储双写,你只要是双写,就一定会有数据一致性的问题,那么你如何解决一致性问题?
- 双写一致性,你先动缓存redis还是数据库mysql哪一个?why?
- 延时双删你做过吗?会有哪些问题?
- 有这么一种情况,微服务查询redis无mysql有,为保证数据双写一致性回写redis你需要注意什么?双检加锁策略你了解过吗?如何尽量避免缓存击穿?
- redis和mysql双写100%会出纰漏,做不到强一致性,你如何保证最终一致性?
# 2缓存双写一致性问题
如果redis中有数据
需要和数据库中的值相同
如果redis中无数据
数据库中的值要是最新值,且准备回写redis
# 2.1缓存按照操作来分,细分2种
- 只读缓存
- 读写缓存
- 同步直写策略
- 写数据库后也同步写redis缓存,缓存和数据库中的数据⼀致;
- 对于读写缓存来说,要想保证缓存和数据库中的数据⼀致,就要采⽤同步直写策略
- 异步缓写策略
- 正常业务运行中,mysql数据变动了,但是可以在业务上容许出现一定时间后才作用于redis,比如仓库、物流系统
- 异常情况出现了,不得不将失败的动作重新修补,有可能需要借助kafka或者RabbitMQ等消息中间件,实现重试重写
- 同步直写策略
# 2.2 代码实现
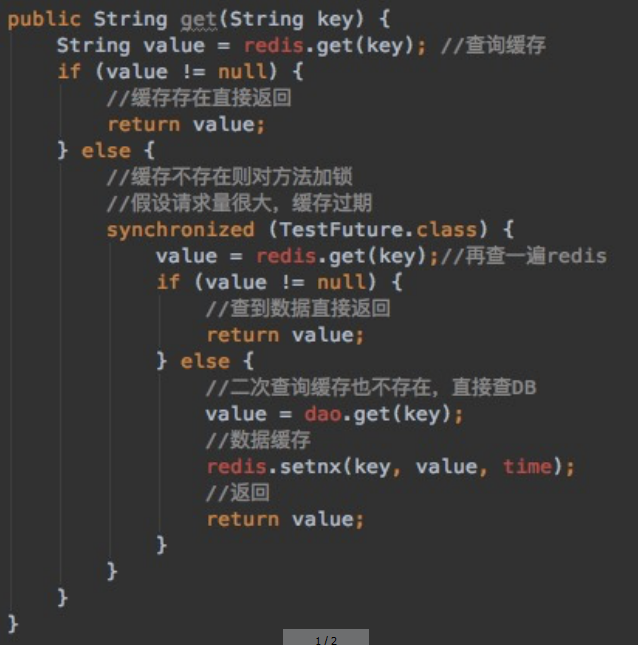
问题
多个线程同时去查询数据库的这条数据,那么我们可以在第一个查询数据的请求上使用一个 互斥锁来锁住它。
其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后做缓存。
后面的线程进来发现已经有缓存了,就直接走缓存。
code
@Service @Slf4j public class UserService { public static final String CACHE_KEY_USER = "user:"; @Resource private UserMapper userMapper; @Resource private RedisTemplate redisTemplate; /** * 业务逻辑没有写错,对于小厂中厂(QPS《=1000)可以使用,但是大厂不行 * @param id * @return */ public User findUserById(Integer id) { User user = null; String key = CACHE_KEY_USER+id; //1 先从redis里面查询,如果有直接返回结果,如果没有再去查询mysql user = (User) redisTemplate.opsForValue().get(key); if(user == null) { //2 redis里面无,继续查询mysql user = userMapper.selectByPrimaryKey(id); if(user == null) { //3.1 redis+mysql 都无数据 //你具体细化,防止多次穿透,我们业务规定,记录下导致穿透的这个key回写redis return user; }else{ //3.2 mysql有,需要将数据写回redis,保证下一次的缓存命中率 redisTemplate.opsForValue().set(key,user); } } return user; } /** * 加强补充,避免突然key失效了,打爆mysql,做一下预防,尽量不出现击穿的情况。 * @param id * @return */ public User findUserById2(Integer id) { User user = null; String key = CACHE_KEY_USER+id; //1 先从redis里面查询,如果有直接返回结果,如果没有再去查询mysql, // 第1次查询redis,加锁前 user = (User) redisTemplate.opsForValue().get(key); if(user == null) { //2 大厂用,对于高QPS的优化,进来就先加锁,保证一个请求操作,让外面的redis等待一下,避免击穿mysql synchronized (UserService.class){ //第2次查询redis,加锁后 user = (User) redisTemplate.opsForValue().get(key); //3 二次查redis还是null,可以去查mysql了(mysql默认有数据) if (user == null) { //4 查询mysql拿数据(mysql默认有数据) user = userMapper.selectByPrimaryKey(id); if (user == null) { return null; }else{ //5 mysql里面有数据的,需要回写redis,完成数据一致性的同步工作 redisTemplate.opsForValue().setIfAbsent(key,user,7L,TimeUnit.DAYS); } } } } return user; } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
# 3.数据库和缓存一致性的解决方案
目的:总之,我们要达到最终一致性!
给缓存设置过期时间,定期清理缓存并回写,是保证最终一致性的解决方案。
我们可以对存入缓存的数据设置过期时间,所有的写操作以数据库为准,对缓存操作只是尽最大努力即可。也就是说如果数据库写成功,缓存更新失败,那么只要到达过期时间,则后面的读请求自然会从数据库中读取新值然后回填缓存,达到一致性,切记,要以mysql的数据库写入库为准。
# 3.1 四种更新策略
先更新数据库,再更新缓存×
异常1
- 先更新mysql的某商品的库存,当前商品的库存是100,更新为99个。
- 先更新mysql修改为99成功,然后更新redis
- 此时假设异常出现,更新redis失败了,这导致mysql里面的库存是99而redis里面的还是100
异常2
【先更新数据库,再更新缓存】,A、B两个线程发起调用
【正常逻辑】
1 A update mysql 100
2 A update redis 100
3 B update mysql 80
4 B update redis 80
【异常逻辑】多线程环境下,A、B两个线程有快有慢,有前有后有并行
1 A update mysql 100
3 B update mysql 80
4 B update redis 80
2 A update redis 100
最终结果,mysql和redis数据不一致,o(╥﹏╥)o,
mysql80,redis100
先更新缓存,再更新数据库×
业务上一般把mysql作为底单数据库,保证最后解释
异常2
【先更新缓存,再更新数据库】,A、B两个线程发起调用
正常逻辑】
1 A update redis 100
2 A update mysql 100
3 B update redis 80
4 B update mysql 80
【异常逻辑】多线程环境下,A、B两个线程有快有慢有并行
A update redis 100
B update redis 80
B update mysql 80
A update mysql 100
----mysql100,redis80
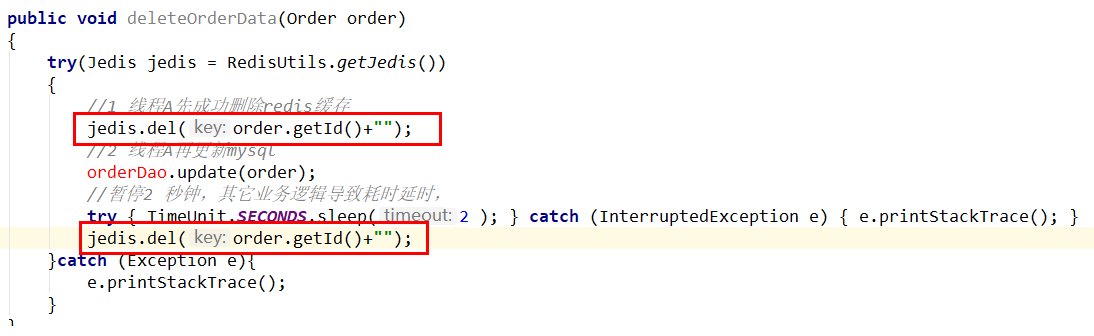
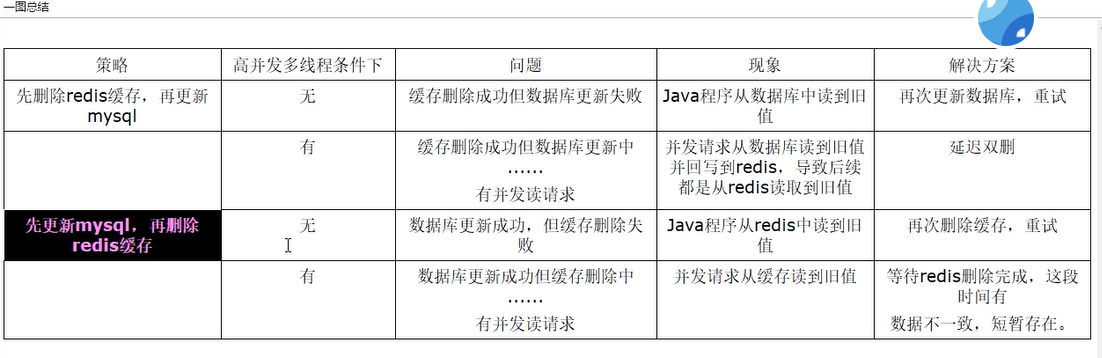
先删除缓存,再更新数据库×
异常为题
(1)请求A进行写操作,删除redis缓存后,工作正在进行中,更新mysql......A还么有彻底更新完mysql,还没commit
(2)请求B开工查询,查询redis发现缓存不存在(被A从redis中删除了)
(3)请求B继续,去数据库查询得到了mysql中的旧值(A还没有更新完)
(4)请求B将旧值写回redis缓存
(5)请求A将新值写入mysql数据库
**上述情况就会导致不一致的情形出现。 **

解决
采用延时双删策略

双删方案面试题
这个删除该休眠多久呢
- 第一种方法:根据业务
第二种方法:新启动一个后台监控程序,比如后面要讲解的WatchDog监控程序,会加时
这种同步淘汰策略,吞吐量降低怎么办?
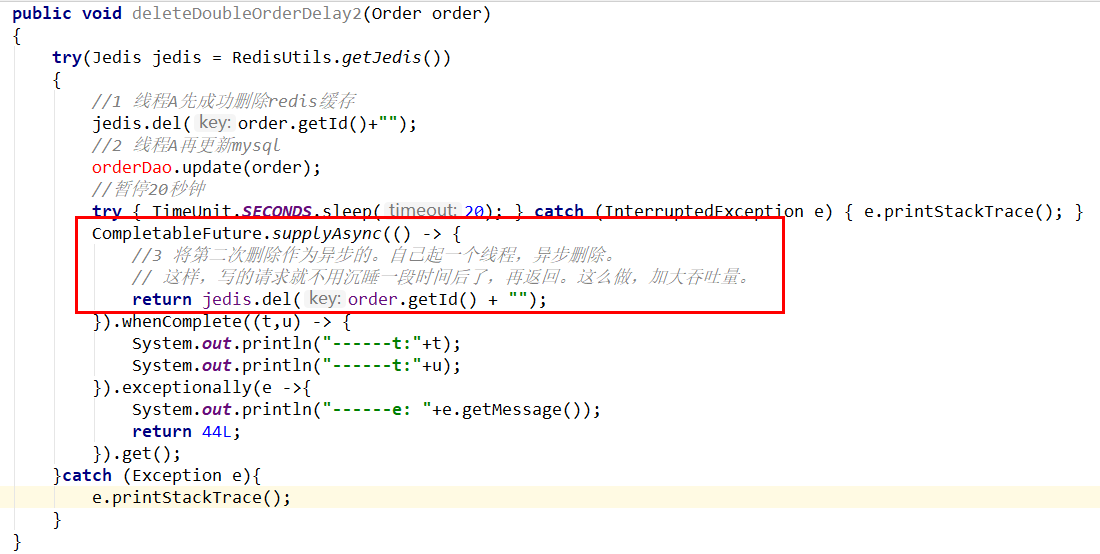
- 后续看门狗WatchDog源码分析
先更新数据库,再删除缓存⭐
异常问题
业务指导
阿里:上述的订阅binlog程序在mysql中有现成的中间件叫canal,可以完成订阅binlog日志的功能。
解决方案
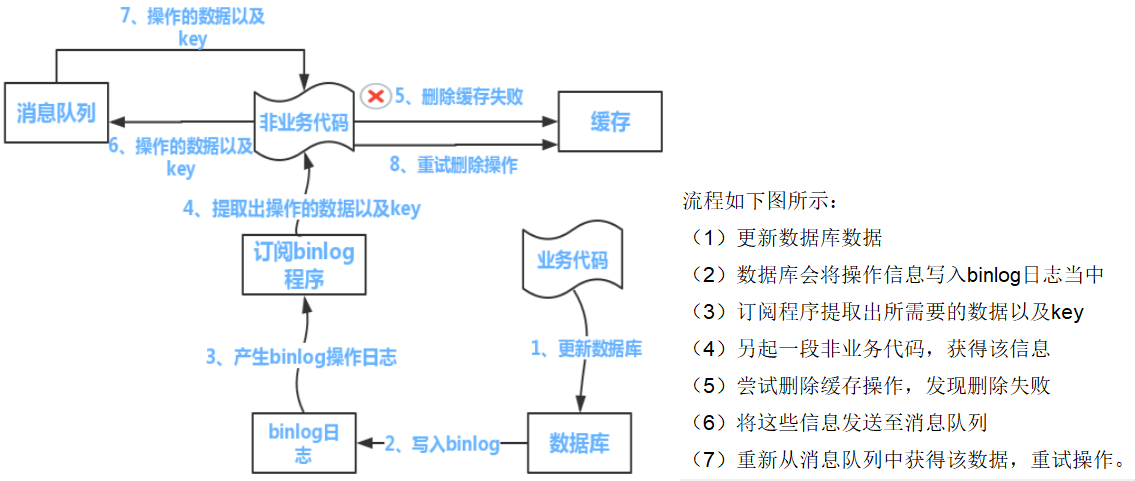
- 可以把要删除的缓存值或者是要更新的数据库值暂存到消息队列中(例如使用Kafka/RabbitMQ等)。
- 当程序没有能够成功地删除缓存值或者是更新数据库值时,可以从消息队列中重新读取这些值,然后再次进行删除或更新。
- 如果能够成功地删除或更新,我们就要把这些值从消息队列中去除,以免重复操作,此时,我们也可以保证数据库和缓存的数据一致了,否则还需要再次进行重试
- 如果重试超过的一定次数后还是没有成功,我们就需要向业务层发送报错信息了,通知运维人员。
答案
- 最终一致性
- 流量充值,先下发短信实际充值可能滞后5分钟,可以接受
- 电商发货,短信下发但是物流明天见